
Did you know that the power of collective wisdom can outperform even the sharpest individual minds?
Imagine applying that principle to your data—where a single decision-making process evolves into a forest of insights, each working together to deliver more accurate predictions.
That’s the magic behind Random Forest algorithms.
It’s not just one tree making a call; it’s an ensemble of decision-makers working in harmony.
Let’s break down how Random Forests can transform your approach to data-driven decisions and why this algorithm stands out in machine learning.
Key-Takeaways:
- What Are Decision Trees?
- Decision trees simplify complex decision-making by breaking it into step-by-step processes.
- What is Random Forest?
- Random Forest is an ensemble method combining multiple decision trees for more robust and accurate predictions.
- How Does Random Forest Work?
- It uses a voting mechanism among decision trees to reduce bias, improve accuracy, and prevent overfitting.
- Pros and Cons of Random Forest:
- Pros: Improved accuracy, reduced overfitting, robustness to noise, and insights into feature importance.
- Cons: High computational complexity and less interpretability compared to simpler models.
- Key Differences:
- Decision Trees work independently, while Random Forest combines multiple trees for consensus.
- Bagging enhances Random Forest by introducing randomness and reducing overfitting.
- Applications:
- Random Forest excels in both classification (categorical predictions) and regression (continuous outcomes).
- Tuning Random Forest:
- Optimal performance depends on hyperparameters like the number of trees, max depth, and feature subset size.
What Are Decision Trees?
Choices.
I’m sure you have faced the struggle of deciding on something, and we know how making the right choice can be a challenge at times.
Do you know Decision trees can help us out during such occasions?
This is because Decision trees work like step-by-step guides for decision-making.
Each branch of the tree represents a different option or outcome based on specific factors or questions.
Putting it simply, It's like following a path of choices to reach a final decision, making them useful for straightforward decisions you can follow.

How can we take the idea of decision trees to the next level?
This is where ensemble methods like Random Forest kicks in, which combine multiple trees to create even more accurate predictions.
What is Random Forest?
Guess what happened when decision trees got even smarter
—they evolved into “Random Forest”, a machine learning algorithm that relies on the power of multiple decision trees to make robust predictions you can rely on.
Think of it like assembling a group of experts, each offering a unique perspective on a problem.
Instead of relying on a single tree, Random Forest aggregates the opinions of many trees, resulting in more reliable outcomes.
It's like tapping into a crowd of knowledgeable friends to guide you toward the best decision!

Now that you know what Random Forest is, let’s talk about how it works.
How Does Random Forest Work?
We’ve discussed how Random Forest combines a wide selection of opinions (trees) to come up with a decision, right?
But how does it get the opinions when making predictions?
The answer?
It combines perspectives through a voting mechanism to arrive at the most likely outcome.
In the below image you can see that different decision trees come up with their own classification results.
Then finally the random forest algorithm picks the final classification based on “majority voting”.
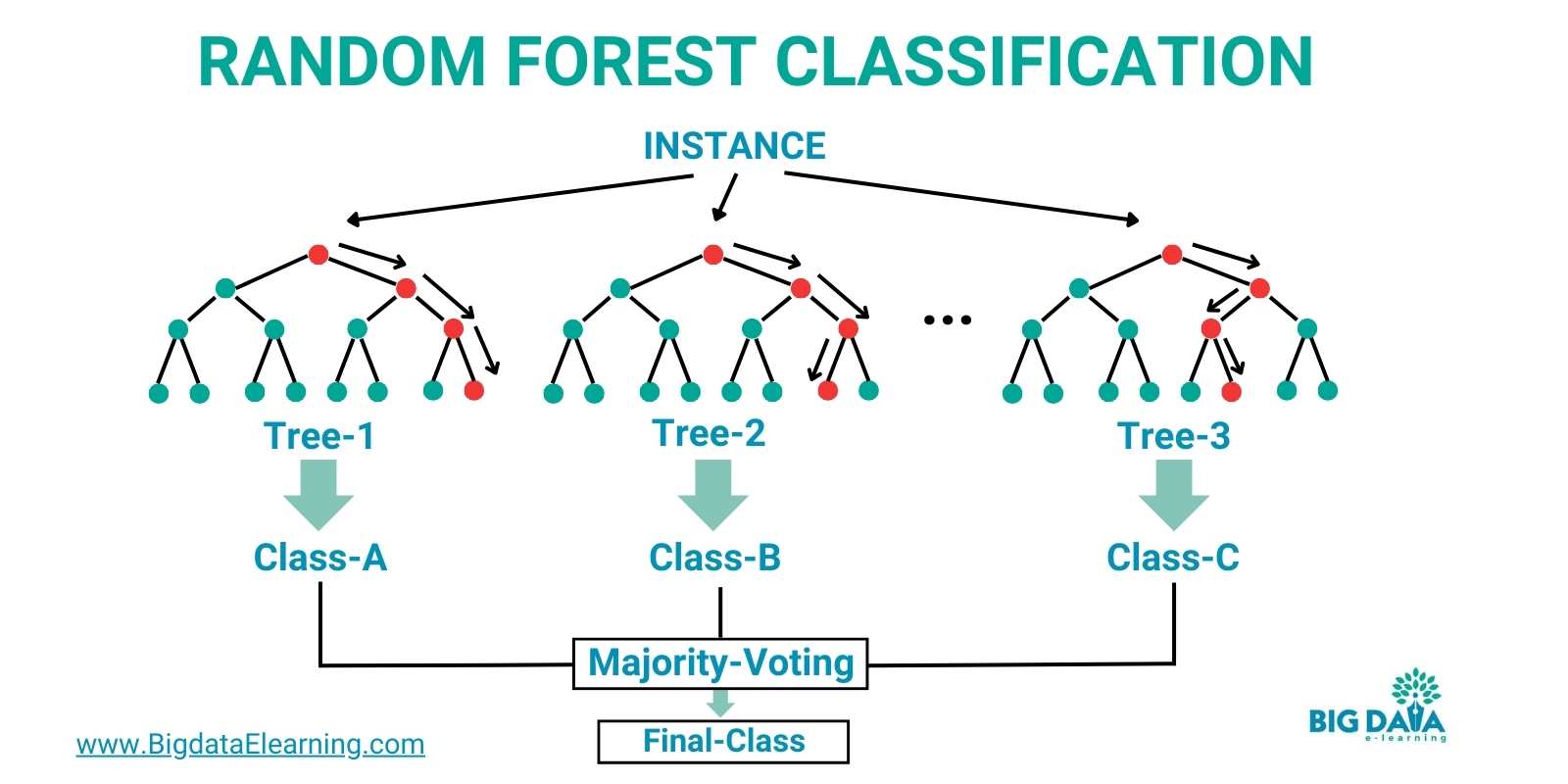
And this approach ensures robust predictions by minimizing the risk of individual biases or errors, resulting in accurate and reliable machine-learning models.
But that begs the question:
Why should you use it?
Let’s look into the pros of random forest algorithm
Pros of Random Forest Algorithm
The Random Forest algorithm offers several reasons to be your go-to choice in machine learning.
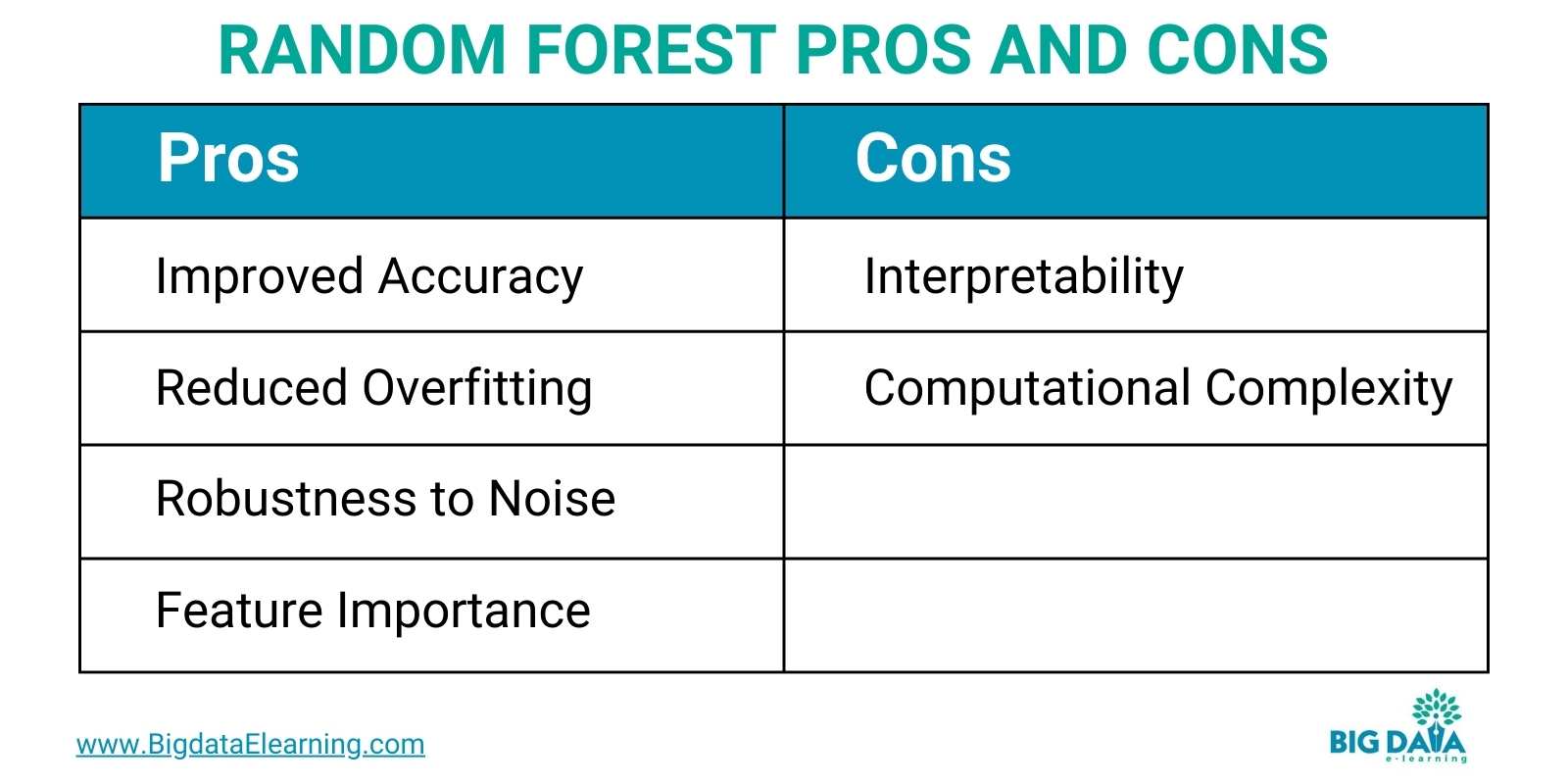
- Improved Accuracy: Firstly, it excels, resulting in more reliable predictions compared to individual models.
- Reduced Overfitting: Secondly, it’s resistant to overfitting, a common issue with decision trees, thanks to their diverse perspectives.
- Robustness to Noise: Additionally, it exhibits robustness in noisy datasets, maintaining stability even when some trees make errors.
- Feature Importance: And lastly, it provides valuable insights into feature importance, aiding in understanding the driving factors behind predictions.
Overall, the Random Forest algorithm stands out for its accuracy and interpretability in complex machine-learning tasks.
Now that we have seen the pros of random forest algorithms, let’s dive into the cons of random forest algorithms.
Cons of Random Forest Algorithm
Well, let’s share the cons of the Random Forest Algorithm.
Cons:
- Interpretability: Due to their complexity, interpreting how Random Forest arrives at decisions can be challenging.
- Computational Complexity: Training can be computationally expensive, especially with large datasets, requiring more resources.
Despite these challenges, Random Forest remains a powerful and popular choice for various machine-learning tasks, offering a balance of accuracy and robustness.
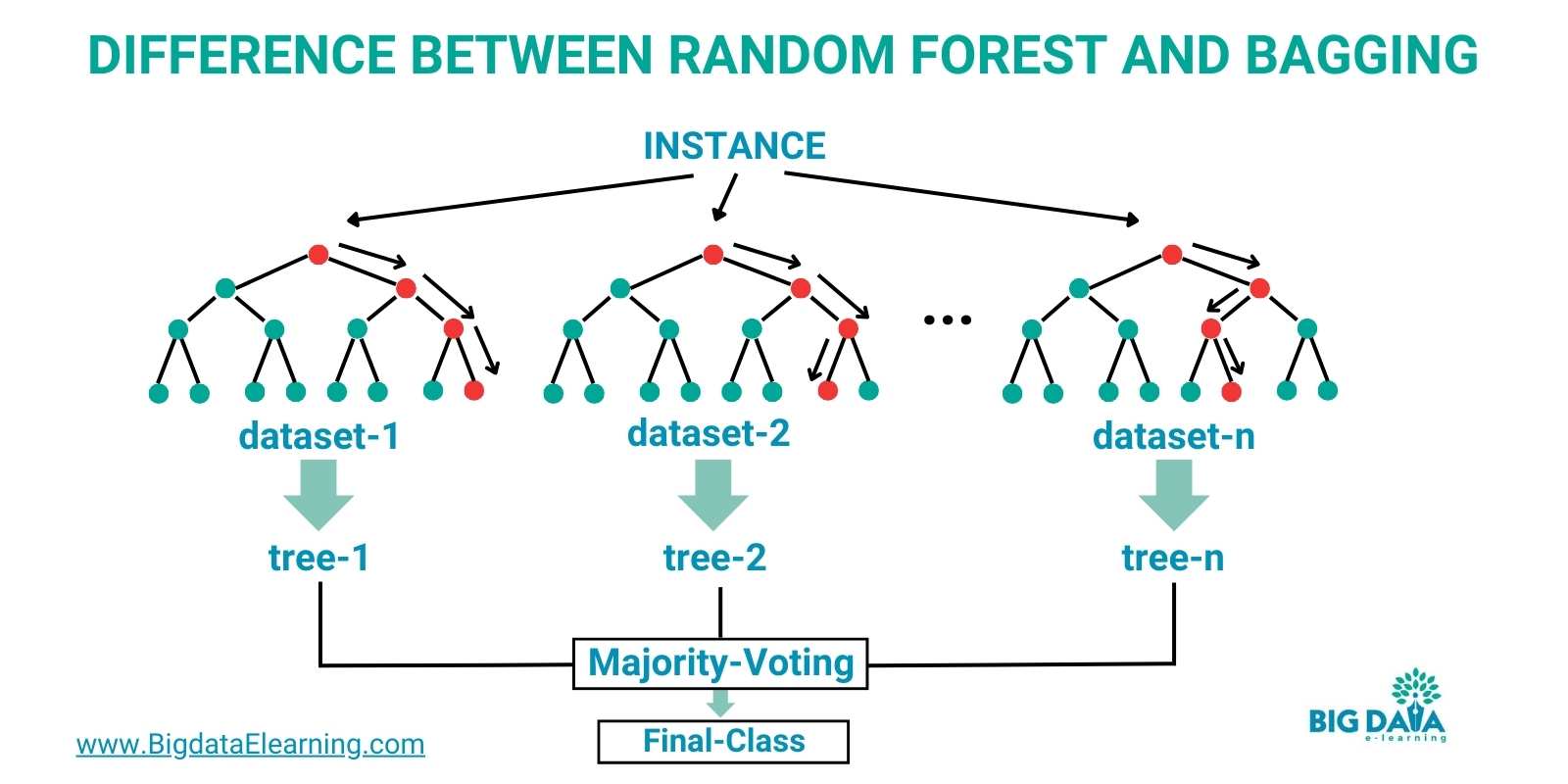
Difference Between a Decision Tree and a Random Forest
Let’s talk about a decision tree and Random Forest.
A decision tree is a single path to a decision. It's simple and makes decisions based on a set of conditions.
Now, picture a Random Forest as a collection of many of these paths. Instead of relying on one path, Random Forest combines multiple.
In essence, a decision tree is a solo artist, while a Random Forest is a group of collaborating artists.
Sounds good?

Difference Between Random Forest and Bagging
Bagging is a short “term” for Bootstrap Aggregating, which involves training multiple instances of the same learning algorithm on different subsets of the training data.
With bagging, you aim to
- reduce variance and
- improve model performance by averaging the outputs of these models.
A well-known application of bagging is the Random Forest algorithm.
Random Forest is an ensemble method that builds multiple decision trees using the bagging technique.
Important Hyperparameters
Now that you know what sets Random Forest apart, let’s dive into some important hyperparameters that control its behavior. Understanding these settings is crucial to fine-tuning the model’s performance.
Hyperparameters are key settings that control the behavior of the Random Forest algorithm.


And just like with many other machine learning algorithms, experimentation, and tuning are often required to find the optimal settings for a specific dataset and task.
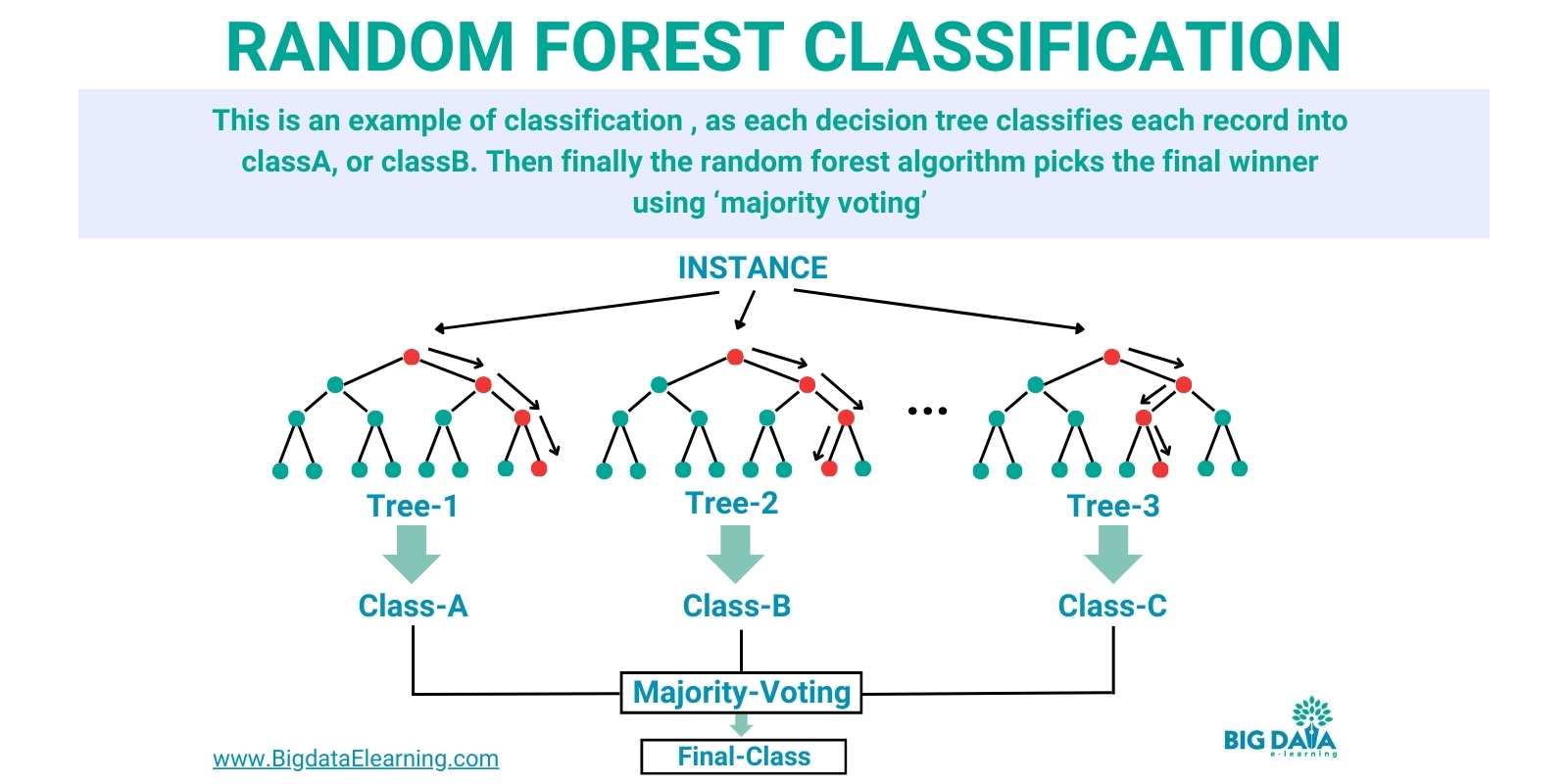
Random Forest Classification
Random Forest is a powerful algorithm you can use for classification tasks in machine learning.
Here's why Random Forest is great for classification:
- Random Forest combines predictions from multiple decision trees, leading to more accurate classification compared to individual trees.
- It's less prone to overfitting because of its ensemble nature, which averages out biases from individual trees.
- Random Forest can provide insights into feature importance, helping to understand which features are most influential for classification.
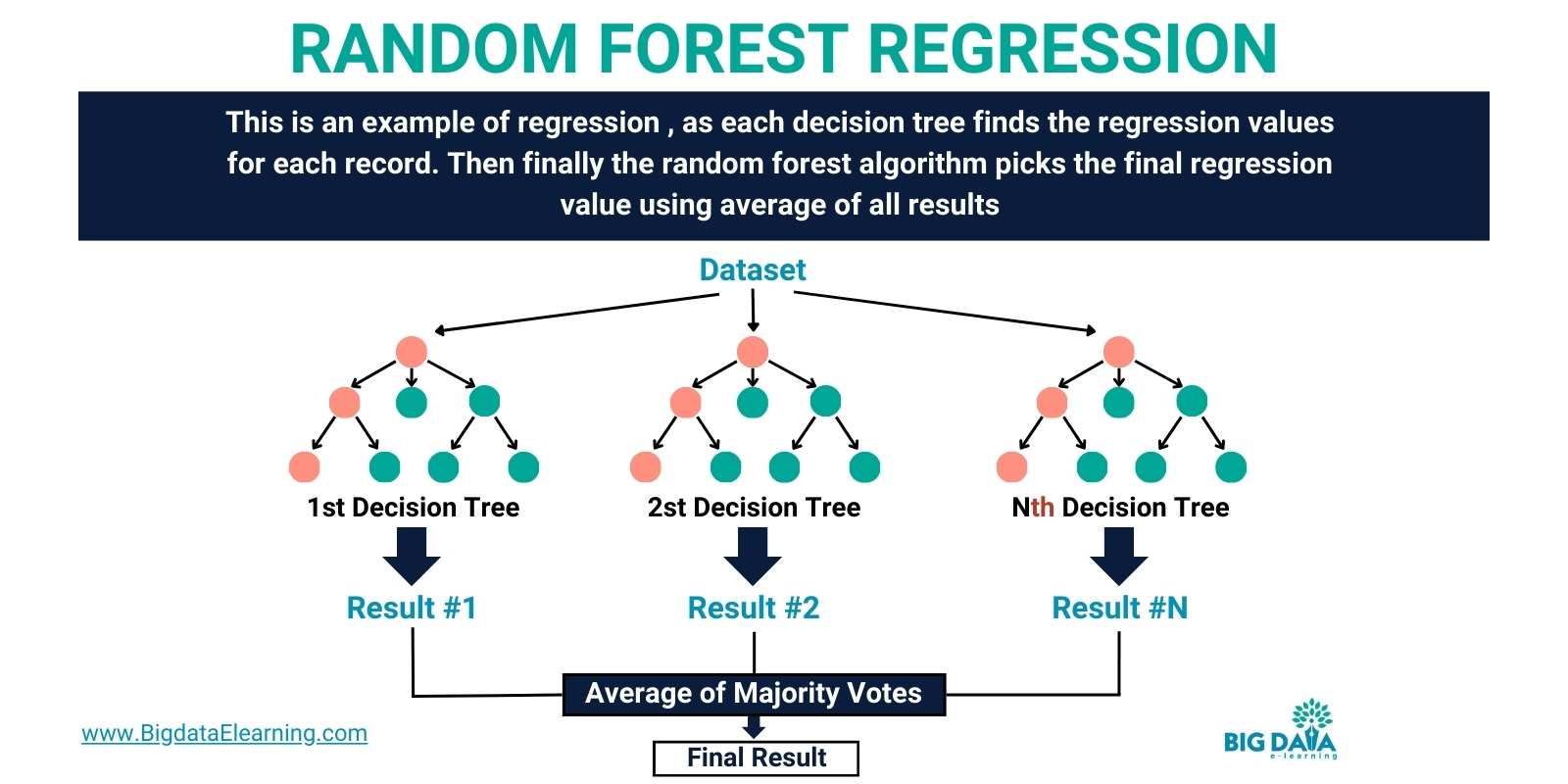
Random Forest Regression
Of course, Random Forest can also be used in regression, as it predicts continuous outcomes (like prices or quantities) based on input variables.
Here's why Random Forest is effective for regression:
- By aggregating predictions from multiple decision trees, Random Forest can provide accurate continuous predictions.
- Unlike individual decision trees, Random Forest is less prone to overfitting, making it suitable for complex datasets.
- It's used in diverse applications like predicting housing prices, stock market trends, and customer lifetime values.
Conclusion
And once again, there you have it!
You’ve now covered the most important information involving Random Forest, summarized into an easy-to-digest blog.
Now you know that:
- Random Forest is a versatile and powerful algorithm used across multiple industries
- It excels in handling complex datasets, reducing overfitting, and providing valuable insights into feature importance.
- Random Forest is making a significant impact by enabling data-driven decision-making.
In conclusion, Random Forest stands out as a go-to choice for machine learning tasks, offering a balance of accuracy, robustness, and interpretability.
Whether you're a data scientist, researcher, or enthusiast, exploring Random Forest can unlock new possibilities in predictive modeling and analysis.
It sounds complex but like many things, it gets easier the more you get your toes wet.
If you have any questions, feel welcomed to ask and I’ll do my best to help you out!
You’ve got this!
Stay connected with weekly strategy emails!
Join our mailing list & be the first to receive blogs like this to your inbox & much more.
Don't worry, your information will not be shared.


